new blog
Monday, 11 May 2020
Friday, 17 April 2020
.gitignore is not working
.gitignore가 정상적으로 작동하지 않는다면?
// Delete repository cache all
git rm -r --cached .
// retracking with .gitignore
git add .
// commit
git commit -m "fixed untracked files"Monday, 6 January 2020
자율주행기술 현황
국외 자율주행기술 현황
자율주행 기술 개발은 기술 R&D보다는 상용화 및 제품 생산에 초점을 맞추고 있어 새발 속도가 가속화되고 있다. 글로벌 시장업체인 네비갠트 리서치(Navigant Research)는 자율주행기술 및 플랫폼을 개발하고 있는 세계 주요 19개 업체를 대상으로 경쟁력을 조사한 보고서를 발간하였다. 비전과 시장진입 전략, 파트너십, 생산 전략, 기술, 매출/마케팅/유통, 제품 품질 및 신뢰성 등에 의해 경쟁력을 비교하여 선두, 경쟁, 도전, 하위 그룹으로 구분한다. GM, 구글 Waymo, Daimler, Ford 등이 선두 그룹을 형성하였고, PSA, Toyota, Volvo, Baidu, Navya, 현대 등은 경쟁그룹으로, Apple, Uber, 테슬라, 혼다 등은 도전그룹으로 평가되었다.구글 Waymo
구글 자회사 웨이모 (Waymo)는 운전자없이 완전한 자율주행을 할 수 있는 시스템을 만들기위해 운전자의 지속적인 관찰이 필요한 차선 유지 등과 같은 문제를 해결하려고 노력중이다. 현재는 특정 조건에서만 운전자의 관찰이 필요한 미국자동차공학회(SAE) 기준 레벨 4의 자율주행 시스템을 완성하였다. 웨이모는 라이다와 카메라, 레이더 그리고 기타 부수적인 센서를 이용해 자동차 주변의 장애물과 사건을 인식하고 반응하는 시스템을 구축하였다.웨이모의 자율주행 소프트웨어는 크게 3가지로 관찰 단계, 행동 예측 단계, 계획 단계로 나눌 수 있다. 관찰 단계에서는 도로 주변의 물체들을 인식하고 무엇인지 구분하며 그 물체들의 속력, 방향, 가속도를 측정한다. 행동 예측 단계에서는 인식한 물체들이 도로 주변에서 어떻게 행동할지 예측한다. 웨이모는 수백만 마일을 주행한 경험을 바탕으로 예측할 수 있다. 계획 단계에서는 앞 두 단계에서 얻은 정보를 바탕으로 자동차가 어떤 길로 가야할지 계획한다. 이들은 경험상 방어적이고 소심한 운전이 가장 안전하다고 생각한다.
웨이모 시스템은 도로 종류, 거리, 차원 등 물리적 환경에 대한 깊은 이해로 실시간 정보를 통해 지도를 만들고 차의 위치를 파악할 수 있다. 뿐만 아니라 시범 주행을 통해 얻는 데이터를 수집하고 해석하는 시스템도 갖추고 있다. 인터넷 연결로 인한 해킹을 방어하는 시스템도 개발하였다.
테슬라 Tesla Autopilot
테슬라 오토파일럿(Autopilot)은 차선 유지, 자동차 컨트롤, 자율 주차, 운전자의 확인을 전제한 차선 변경 등을 제공하는 테슬라의 자율주행 시스템 및 하드웨어이다. 테슬라는 완전 자율 자동차를 제공하는 것을 목표로 하고 있다.향상된(Advanced) 오토파일럿은 교통 상황에 속도를 맞추고 차선을 유지하며, 운전자의 개입 없이도 스스로 차선을 변경한다. 또 하나의 간선도로에서 다른 간선도로로 옮겨가고 목적지에 근접하면 스스로 간선도로를 빠져나가며 자율 주차가 가능하다.
국외 공개 자율주행플랫폼 현황
Baidu Apollo
바이두는 2018년 7월 자율주행플랫폼 '아폴로 3.0'을 공개했다. '아폴로 3.0'은 미국 자동차공학회(SAE) 기준 레벨4 수준이다. 레벨4는 운전자의 개입이 필요 없는 수준이지만 만일의 상황을 대비해 운전자가 탑승해야 한다. '아폴로 3.0'에는 개발자와 파트너가 3개월 이내 자율주행차량을 개발할 수 있는 프로그램이 탑재되었다. 이 프로그램은 자율주행 주차, 무인 자율주행 배달, 무인 자율주행 셔틀 서비스로 3가지이다.주차대행의 경우 카메라, 초음파 레이더만 추가하면 모든 차량이 약 1509달러(약 168만원)의 비용으로 자율주행 주차 서비스를 이용할 수 있다. 또 자동조종 키트, 보안시스템, 운영 스케줄링 솔루션을 활용할 수 있다. 여기에 바이두의 음성인식 소프트웨어와 얼굴인식 기술, 피로감 징후 모니터링 기술, 맞춤 서비스 등 흥미로운 기술도 탑재됐다.
이 기술을 바탕으로 바이두는 올해 소프트뱅크 자회사 SB드라이브와 협력해 일본과 중국의 베이징, 심천, 우한 등 일부 도시에서 14인승 자율주행 미니버스 '아폴롱' 10대를 시범 운행할 방침이다. 아폴롱에는 바이두의 자율주행플랫폼 아폴로가 탑재됐다.
Autoware Foundation Autoware
오토웨어(Autoware)는 일본 나고야 대학과 나가사키 대학이 공동으로 개발하여 2015년 8월에 공개되었으며 현재에도 활발히 개발되고 있다. 오토웨어는 로봇 소프트웨어 플랫폼인 ROS(Robot Operation System)을 기반으로 개발된 응용 소프트웨어이다. 오토웨어는 라이다를 이용하여 만들어진 3차원 점지도가 미리 주어질 때, 주행 중에 라이다로부터 얻어진 3차원 점군 데이터를 이와 비교하여 차의 위치를 실시간으로 파악할 수 있다. 위치가 파악되면 목적지까지의 주행 경로를 계획하고 조향 휠, 가속 페달, 브레이크 페달, 기어 스틱 등을 제어해 자율 주행을 수행할 수 있다.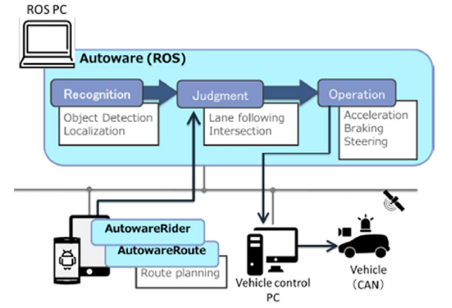
그림은 오토웨어의 동작과정을 개략적으로 보여준다. 첫째, 인식 단계에서는 라이다를 이용하여 3차원 점지도 상에서 자차 위치를 파악하고 카메라와 함께 장애물을 인식하다. 둘째, 판단 단계에서는 파악된 정보와 입력된 최종 목적지 정보를 기반으로 안전한 주행 경로를 계획하고 주행 차선, 교차로 진입 차선 등을 결정한다. 셋째, 주행 단계에서는 주어진 주행 경로에 따라 실시간으로 자동차의 목표 조향각과 목표 속도를 결정하고 차량 제어 컴퓨터에 전달한다. 마지막으로 차량 제어 컴퓨터는 전달받은 목표를 달성하기 위해서 휠, 가속 페달, 브레이크 페달 등을 조작한다.
국외 자율주행기술 검증 프로세스 현황
Mcity Test Facility 미국 미시간 대학
Mcity Test Facility는 도시 및 교외 환경에서 자율주행자동차와 기술을 테스트 및 시뮬레이션 하기위해 제작된 테스트 장소이다. Mcity는 미시간 교통부와 협력하여 도시 및 교외 환경에서 마주치는 복잡한 차량들을 모사하는 독특한 테스트 시설을 설계했다. Mcity는 약 16에이커의 도로와 교통 인프라를 갖춘 미시간 대학의 노스(North) 캠퍼스 부지에 자리하고 있다. 교차로, 교통 표지판, 신호, 보도, 건물, 가로등, 건설 장벽 등 장애물이 있는 약 5개의 차선을 갖추고 있다.Centre of Excellence for Testing & Research of AVs (CETRAN) 싱가폴
싱가폴의 난양공과대학교(Nanyang Technological Univercity)가 이끄는 CETRAN(Centre of Excellence for Testing & Research of AVs)은 자율주행기술을 직접 개발하지는 않지만 자율주행시스템이 어떻게 작동해야 하는지, 테스트는 어떻게 해야 하는지, 자율주행 자동차에 대한 국제 기준은 어떻게 만들어져야 하는지에 대해 연구한다. CETRAN은 자동차 승객의 안전을 가장 먼저 고려하며, 대중교통 등 사회가 자율주행자동차를 신뢰하게 만드는 것이 이들의 목표이다.American Center for Mobility (ACM) 미국 미시간
ACM(American Center for Mobility)은 500에이커가 넘는 다양한 자율주행 테스트 환경을 제공한다. ACM은 자율주행자동차에 대한 테스트, 검증, 교육, 제품 기준 개발 등을 위해 설립된 글로벌 센터이다. 모든 기업, 정부, 대학 등에서 사용할 수 있다.A Puzzle of Clever Connections Nears a Happy End
Happy Ending Problem은 5개의 주어진 점이 있고 어떤 세 점도 한 줄 위에 있지 않다면 볼록 다각형인 사각형을 만들 수 있다는 것이다. 이것은 사실이다. 하지만 볼록다각형인 오각형, 육각형 혹은 11각형을 만들어야 한다면 얼마나 많은 점이 필요할까?
세 명의 젊은 수학자는 3,4,5각형일 때의 경우를 풀었다. 5개의 점이 4각형을 만들고, 9개의 점이 5각형을 만들 수 있다. 그들은 2^(n–2) + 1개의 점이 볼록 다각형 n각형을 만들 수 있다고 생각했다. 그리고 이것을 증명하는데에 $500를 걸었다.
몇십년이 흐르는 동안, 17개의 점이 볼록다각형 6각형을 보장한다는 것 외에 진전이 없었다. 그리고 이 문제가 나타난지 80여년이 지나서야 드디어 2^(n–2) + 1개의 점이 볼록 다각형 n각형을 만들 수 있다는 것이 증명되었다.
그들은 이 논문에서 컵-캡 정리를 증명했다. 컵-캡 정리는 점이 적어도 몇 개 필요한지 컵 또는 캡의 사이즈를 정하기 전에 알려준다. 게다가 Happy Ending Problem의 상한을 정할 수 있다. 그들은 이 정리를 통해 4^n개의 점이 n sided convex polygon을 만든다는 것을 알았다. 하지만 이 상한은 여전히 크다.


Suk의 작업은 Erdős and Szekeres’ conjecture 가 거의 맞다는 것을 보여줬다. 기존의 상한은 4^n이었던데 반해, Suk은 상한을 2^(n+6n^(⅔)log n) 까지 제한하는데 성공했다.
작년에 나는 두명의 친구와 함께 맨해튼에 있는 방 3개 짜리 아파트로 이사했다. 월세도 합리적이었고, 위치가 특히 편했다. 집을 구하는 것도 힘들었지만 우리는 또 다른 문제에 직면했다. 바로 누가 어떤 방을 쓸 것인가에 관한 것이었다.
각 방은 각각 다른 크기를 가지고 있었다. 두 방은 거리를 향한 북향이고 가장 작은 방은 뒷골목을 향했다. 가장 큰 방은 두 개의 창문이 있고, 두번째로 큰 방은 화재대피로와 연결된다.
사람들은 주거비를 아끼기 위해 전혀 알지도 못하는 사람들과 살기도 한다. 월세를 똑같이 나눌지, 방 크기에 따라 나눌지 아니면 수입에 따라 나눌지도 정해야 한다.
그래서 학계에서는 공평하게 나누는 법을 연구했다. 연구자들은 어떤 방법에도 만족하지 못했다.
문제는 개개인이 각 방을 다르게 평가한다는 것이다. 나는 자연광을 굉장히 고려하지만 다른 사람들은 그렇지 않았다. 옷장을 갖는 것보다 가치가 있는 일인지? 어떤 이는 방 모양을, 다른 이는 화장실 유무를 더 크게 고려했다.
방의 크기나 각 개인의 선호도를 전부 고려하지 못하다 보니 뾰족한 수가 없는 협상은 갈등과 서운함만을 불러올 뿐이었다.
나는 우리의 월세를 나누는 더 좋은 방법을 찾기 위해 고민했다. 그렇게 Harvey Mudd 대학의 수학 교수인 Francis Su의 논문까지 보게 되었다. 수학적으로 어떻게 분할할 것인가를 고민한 Sperner’s lemma에 관한 논문이었다.
Su 박사는 1999년 논문 "Rental Harmony : Sperner’s Lemma in Fair Division."(조화로운 월세 내기 : Sperner’s lemma를 적용한 공평한 나누기)에서 Sperner’s lemma와 월세 나누기의 연관성을 처음으로 제시했다. 그는 하버드에서 박사학위를 마칠 때 쯤 이 문제를 연구하기 시작했다. 그의 친구가 나와 똑같은 곤경에 처해 있었고, 그에게 조언을 구했기 때문이다.
Su 박사는 어쩌면 이 문제가 자신이 들어본 다른 문제와 연관이 있을 수도 있을 것이라는 생각을 하게 된다.
세 명의 젊은 수학자는 3,4,5각형일 때의 경우를 풀었다. 5개의 점이 4각형을 만들고, 9개의 점이 5각형을 만들 수 있다. 그들은 2^(n–2) + 1개의 점이 볼록 다각형 n각형을 만들 수 있다고 생각했다. 그리고 이것을 증명하는데에 $500를 걸었다.
몇십년이 흐르는 동안, 17개의 점이 볼록다각형 6각형을 보장한다는 것 외에 진전이 없었다. 그리고 이 문제가 나타난지 80여년이 지나서야 드디어 2^(n–2) + 1개의 점이 볼록 다각형 n각형을 만들 수 있다는 것이 증명되었다.
Split Shapes
이 문제는 볼록다각형을 만드는 변들을 찾는 것으로 볼 수 있다. 1935년의 논문에서 그들은 u shape모양을 Cup라고 하였고, n shape 모양을 Cap이라고 하였다. 그래서 볼록다각형을 만들 때는 cup 위에 cap을 붙이면 된다. 이를 이용하면, 볼록다각형을 확장할 때 어떤 것을 붙일지를 통해 쉽게 생각할 수 있다.그들은 이 논문에서 컵-캡 정리를 증명했다. 컵-캡 정리는 점이 적어도 몇 개 필요한지 컵 또는 캡의 사이즈를 정하기 전에 알려준다. 게다가 Happy Ending Problem의 상한을 정할 수 있다. 그들은 이 정리를 통해 4^n개의 점이 n sided convex polygon을 만든다는 것을 알았다. 하지만 이 상한은 여전히 크다.
Sorting Spikes
Andrew Suk은 Ramsey Theory에 집중했다. 문제에 Ramsey Theory를 적용하면, 잘 정리된 볼록다각형의 point set을 얻을 수 있다.Suk의 작업은 Erdős and Szekeres’ conjecture 가 거의 맞다는 것을 보여줬다. 기존의 상한은 4^n이었던데 반해, Suk은 상한을 2^(n+6n^(⅔)log n) 까지 제한하는데 성공했다.
To Divide the Rent, Start With a Triangle
작년에 나는 두명의 친구와 함께 맨해튼에 있는 방 3개 짜리 아파트로 이사했다. 월세도 합리적이었고, 위치가 특히 편했다. 집을 구하는 것도 힘들었지만 우리는 또 다른 문제에 직면했다. 바로 누가 어떤 방을 쓸 것인가에 관한 것이었다.
각 방은 각각 다른 크기를 가지고 있었다. 두 방은 거리를 향한 북향이고 가장 작은 방은 뒷골목을 향했다. 가장 큰 방은 두 개의 창문이 있고, 두번째로 큰 방은 화재대피로와 연결된다.
사람들은 주거비를 아끼기 위해 전혀 알지도 못하는 사람들과 살기도 한다. 월세를 똑같이 나눌지, 방 크기에 따라 나눌지 아니면 수입에 따라 나눌지도 정해야 한다.
그래서 학계에서는 공평하게 나누는 법을 연구했다. 연구자들은 어떤 방법에도 만족하지 못했다.
문제는 개개인이 각 방을 다르게 평가한다는 것이다. 나는 자연광을 굉장히 고려하지만 다른 사람들은 그렇지 않았다. 옷장을 갖는 것보다 가치가 있는 일인지? 어떤 이는 방 모양을, 다른 이는 화장실 유무를 더 크게 고려했다.
방의 크기나 각 개인의 선호도를 전부 고려하지 못하다 보니 뾰족한 수가 없는 협상은 갈등과 서운함만을 불러올 뿐이었다.
나는 우리의 월세를 나누는 더 좋은 방법을 찾기 위해 고민했다. 그렇게 Harvey Mudd 대학의 수학 교수인 Francis Su의 논문까지 보게 되었다. 수학적으로 어떻게 분할할 것인가를 고민한 Sperner’s lemma에 관한 논문이었다.
Su 박사는 1999년 논문 "Rental Harmony : Sperner’s Lemma in Fair Division."(조화로운 월세 내기 : Sperner’s lemma를 적용한 공평한 나누기)에서 Sperner’s lemma와 월세 나누기의 연관성을 처음으로 제시했다. 그는 하버드에서 박사학위를 마칠 때 쯤 이 문제를 연구하기 시작했다. 그의 친구가 나와 똑같은 곤경에 처해 있었고, 그에게 조언을 구했기 때문이다.
Su 박사는 어쩌면 이 문제가 자신이 들어본 다른 문제와 연관이 있을 수도 있을 것이라는 생각을 하게 된다.
The prize in economic sciences 2012
The prize in economic sciences 2012
현실과 시장경제에서 자원들을 어떻게 잘 매칭할 수 있을까? 예를 들어 이런 경우가 있다. 학생들이 다음 교육기관에 어떻게 진학할 것인가? 학교마다 정원이 정해져 있으므로 모든 학생이 원하는 학교 갈 수는 없을 것이다. 기증받은 장기를 어떤 환자에게 이식할 것인가? 장기의 수가 부족하니 가장 효율적인 방법을 찾아야 할 것이다. 2012년 노벨 경제학상을 받은 Alvin Roth와 Lloyd Shapley가 해결했다.
Matching Theory
Gale과 Shapley는 matching을 분석하기 위해 쉽게 그릴 수 있는 예시인 결혼을 생각했다. 여기서 stable matching은 어떤 커플도 깨지고 싶지 않아하는 상태를 말할 수 있다. 이 예시는 이렇게 설정된다. 1. 남자나 여자가 프로포즈를 하는데 가장 선호하는 사람에게 한다. 2. 가장 선호하는 사람에게 프로포즈를 받으면 수락하고 나머지는 거절한다. 3. 거절당하면 다음으로 선호하는 사람에게 프로포즈를 한다. 모두가 짝을 만날 때까지 반복한다. Gale과 Shapley는 이 알고리즘이 언제나 stable matching을 만들어 낸다는 것을 보였다.Evidence
미국 의대생들이 졸업 전에 병원과 어떻게 match될 것인가에 대한 문제이다. 학생들을 놓치지 않기 위해 offer시기가 점점 빨라져 학생들이 충분히 자격을 갖추기 전에 계약이 진행되었고, 학생들은 다음에 어떤 기회가 있는지 알지도 못한 상태로 결정을 내려야 했다. Gale-Shapley Algorithm과 밀접한 NRMP가 해결했다.Matching students and high-schools
Gale-Shapley 알고리즘은 상급학교 진학 등 다른 응용 문제에도 유용하다. 가장 가고 싶은 학교 5개를 정하고 같은 알고리즘으로 최선의 선택을 만들어낼 수 있다. 오늘날에도 많은 지역들이 Gale-Shapley 알고리즘의 다양한 변형을 이용하고 있다.Matching kidneys and patients
지금까지는 matching의 주체 양 쪽 모두가 의지를 갖고 있는 경우를 보았다. 장기이식의 경우는 조금 다른데, 한 쪽은 완전히 Passive하다. Top trading cycle 이라고 하는 이 알고리즘은 initial allocation과 subsequent swapping이 핵심이다.Graph Theory in the Information Age
Graph Theory in the Information Age
그래프 이론은 그래프라고 하는 수학 구조를 공부하는 것을 말한다. 200년 역사 중 지난 10년 간 그래프 이론은 엄청난 변화를 겪었다. WWW의 웹 페이지들과 하이퍼링크들을 그래프 요소인 vertex와 edge로 보면 그래프 이론을 기반으로 웹 관련 알고리즘들을 만들 수 있었던 것이다. 훨씬 크고, 복잡하고, 방대한 그리고 실생활에 아주 밀접한 그래프를 다루는 'network science'가 등장했다. 네크워크의 많은 정보들을 다루려고 하다보니, 새로운 고민들이 생겼다. 이렇게 큰 네트워크는 구조를 어떻게 그려야하지? 어떻게 발전시키지? 그래프 작동의 기본적인 원리는 무엇일까? 이런 질문에 답하기 위해서 비록 충분하지는 않지만 먼저 기존 그래프 이론을 깊이 탐구하였다.Random Graph Theory for General Degree Distributions
Erdos 와 Renyi 는 n개의 점 위에 정의된 그래프로서 두 점을 잇는 선분의 발생 확률을 p 로 주어 만들어지는 그래프 G(n, p) 를 랜덤 그래프의 모델로 선정하였다. 랜덤 그래프는 n 개의 점들 위에서 정해진 확률에 따라 선분이 한 개씩 늘어나면서 진화하는(evolve) 유기체로 이해될 수도 있다. 그렇다면 그래프가 진화하는 동안 어느 시점에 어떤 특정한 성질을 갖게 될까?Random Subgraphs in Given Host Graph
많은 네트워크가 log n 이하의 작은 지름을 가지는데, 이를 small world phenomenon이라고 한다. 랜덤한 서브 그래프들을 다루는 방법 중 하나에는 여과하기 방법이 있다. 확률 threshold를 정하고 넘지 못하는 bond는 삭제하는 것이다. 이 방법으로 전염병의 확산 등을 알 수 있다.PageRank and Local Partitioning
실제 세상을 표현한 그래프는 기본적으로 small world phenomenon이기 때문에 각 점들은 매우 짧은 path로 연결되어 있다. 1998년 Brin과 Page는 구글 웹 서치를 위해 PageRank라는 알고리즘을 고안했다. 페이지랭크는 더 중요한 페이지는 더 많은 사이트와 연결되었다는 사실을 이용하고 있다.Network Games
아침마다 모든 사람들이 제일 빠르고 편한 길을 찾듯이, 게이머들은 기본적으로 이기기 위한 이기적인 플레이를 한다. 고전 그래프 이론은 게임의 입장에서 볼 수 도 있다. 예를 들어 인접한 점들은 다른 색을 가져야 하는 색칠하기 등이 있다.Friday, 3 January 2020
Evolutionary Approach to Approximate
Digital Circuits Design
1
This paper proposed the automatic design process to evolve approximate digital circuits that show a minimal error for a supplied amount of resources.

2
First of all, let’s try to understand the title.
The paper proposed the evolutionary approach to design digital circuits.
But what does ‘Approximate’ mean?
Approximate computing is a new design paradigm to make a computer system with better performance and better energy efficiency. The circuits that are intentionally designed to save energy, performance, or area are called approximate circuits.
The paper proposed the evolutionary approach to design digital circuits.
But what does ‘Approximate’ mean?
Approximate computing is a new design paradigm to make a computer system with better performance and better energy efficiency. The circuits that are intentionally designed to save energy, performance, or area are called approximate circuits.
There were some basic design techniques like over-scaling and functional approximation so far. In the case of over-scaling, circuits are designed to be working perfectly under a normal environment and their energy consumption can be reduced by voltage over-scaling which is using deliberately lower power supply voltage.
Functional approximation means that the circuit is designed not to fully implement the logic behaviours by the specification. A simple method is to reduce the precision of computations in the case of arithmetic circuits by ignoring the least significant bits. For example, the original function F is replaced by G whose implementation leads to energy, delay, area reduction and non-zero error.
Functional approximation means that the circuit is designed not to fully implement the logic behaviours by the specification. A simple method is to reduce the precision of computations in the case of arithmetic circuits by ignoring the least significant bits. For example, the original function F is replaced by G whose implementation leads to energy, delay, area reduction and non-zero error.
3
Of course, the manual redesign is not efficient, automatic methods with some heuristics are currently being developed. SALSA, short for the systematic methodology for the automatic logic synthesis of circuits, introduces the function takes the outputs from the original and approximate circuits and decides if the conditions are satisfied. Another approach SASIMI, short for substitute-and-simplify, identified signal pairs in the circuit. Well, SALSA and SASIMI were not available to the public when this research is on the process. Finally, evolutionary algorithm based methods came out with the hypothesis ‘Better approximations can be discovered than conventional methods can provide.’
4
Why evolutionary approximation? Because it is natural! In the case of the approximation computing, partially working circuits are sought. And evolutionary algorithms can do genetic improving partially working circuits.
Also, evolutionary algorithms are good at multi-objective design as we have learned. In the circuit design, the area, delay and error are optimized together. Constraints are easily handled /which is the error in this case. And It doesn’t need the original circuit which is 100% accurate.
But there are some problems in the evolutionary design, scalability and runtime. These will be mentioned with the proposed method later.
5
From now on, the overall idea of the proposed method will be introduced. Existing systematic approximate circuit synthesis methods always begin with a fully functional circuit and a given quality constraint, error. Then the fully functional circuit undergoes the approximating procedure and an approximate circuit is generated. The design process is usually repeated for several error values and yielding approximate circuits. However, the area, power consumption, and delay are not directly under the control of the approximating procedure. This is a multiobjective circuit design problem that could be solved by a suitable multiobjective evolutionary algorithm. According to some related works, this will have some difficulties with delivering really compact approximate circuits for complex problem instances because of some reasons.
First, the evolutionary design of non-trivial combinational circuits from scratch is super hard. Only a small fraction of runs usually produce a working circuit because of the very rugged corresponding fitness landscapes. Second, it is even harder to evolve a circuit better than a conventional design. Third, a reasonably reliable estimate of power consumption is important because it can be very time consuming for complex circuits.
Another difficulty is the scalability of the evolutionary circuit design as I mentioned before. In this paper, 2 approaches are adopted to solve this problem. First, complex approximate median circuits are evolved by means of the functional-level evolution. Second, they focus on arithmetic circuits and small approximate circuits are used as building blocks of complex approximate circuits. These small approximate circuits are evolved by CGP short for Cartesian Genetic Programming.
6
These are the main features of the proposed method. The direct control of the resulting area and power consumption/ could be very useful for scenarios like/ computing with the minimum error with a power budget. So, the proposed method generates approximate circuits as a function of the area rather than the error. This area-oriented approach cannot be accomplished by conventional circuit design tools.
And the procedure is capable of creating an approximation version of a fully functional circuit with n gates. The design procedure is repeated but it is for the various number of gates to obtain different tradeoffs among design objectives.
To implement this procedure, a single-objective Cartesian Genetic Programming is chosen in a functional level evolution. Multiple runs of CGP are performed to find a circuit with the smallest possible error in a certain condition of resource amount.
Also, there are some features to accelerate the whole design process. The initial population is seeded by approximate circuits to find much better solutions than random seeding. Power consumption is computed only for selected best circuits at the end of each CGP runs. Fitness evaluation exploits the idea of a parallel simulation of candidate circuits and binary circuit code. And multiple runs are executed on a computer cluster.
7

Cartesian Genetic Programming(CGP) is a form of genetic programming that uses a graph representation to encode computer programs. In this case, it is about how to represent a circuit in the chromosome. This representation is very simple, flexible and convenient. A candidate circuit is modelled by means of an array of processing nodes arranged in the number of columns and the number of rows. The processing elements can be elementary gates/ or functional level components/ like adders, comparators and shifters. The set of functions implemented by processing elements/ will be denoted GAMMA. The circuit utilizes primary inputs and outputs. Each node input /can be connected /to the output of a previous gate /or one of the primary circuit inputs. A candidate solution /consisting of two input nodes/ is represented in the chromosome with its function,/ and addresses of connected nodes. The last part of the chromosome/ contains no integers specifying the nodes/ or logic constants (‘0’ and ‘1’). It can be directly connected to the primary output.
8

In figure 1, the chromosome represented the multipliers with inputs and the logic constants.
9

The goal of evolution is to maximize the functionality of approximate circuits. In the yellow box, the fitness is defined as the error to be minimized where y is a candidate circuit’s response and t is target response. Isn’t it familiar? This definition is preferred over the Hamming distance.
This is the overall algorithm.
1) The initial population of the size 1 + λ is created.
2) The fitness function f is called for each candidate circuit.
3) The highest-scored candidate circuit is selected as the new parent.
4) and apply a point mutation, λ offspring individuals are generated from the parent.
5) Steps 2–4 are repeated until the termination condition is not satisfied.
10
The heuristic seeding the initial population is based on a local search. Every single gate of C is replaced by a wire connection independently. The fitness values are calculated for all n circuits. The whole procedure is repeated, but now the lower input is connected to the output for all the gates. The circuit producing the smallest error is taken as the seed for CGP.
A natural extension of this heuristic for a circuit in which gates have to be reduced consists of:
1) a random selection and their replacement by wire connections
2) calculating the fitness value of the modified circuit
3) repeating steps random selection /and calculating fitness value/ and outputting the circuit with the best fitness value.
11
Providing a single approximate circuit is not actually the most valuable output of approximate circuit design methods. To find approximate circuits for every possible number of gates, the proposed approximate circuit design flow will call CGP several times. So there are two approaches for embedding the heuristic into CGP /to obtain approximate circuits /containing every number of gates from n to 1. They proposed and compared Random Seeding, Heuristic Seeding 1 and Heuristic Seeding 2.
Random seeding is that all initial populations are randomly generated. Heuristic seeding 1 means that each CGP run is interleaved by a single run of the heuristic procedure removing just one gate from the best-evolved solution. Heuristic seeding 2 means that all requested seeds are generated by the heuristic and independent CGP runs.
Subscribe to:
Comments (Atom)
-
How to run ORB SLAM with KITTI Dataset Monocular Examples 1. Download the dataset ( grayscale images ) from http://www.cvlibs.net/da...
-
 < What I did > How to install ORB_SLAM2 and test it on Ubuntu 16.04 1. Create a new folder mkdir ORB_SLAM cd ORB_SLAM 2. I...
< What I did > How to install ORB_SLAM2 and test it on Ubuntu 16.04 1. Create a new folder mkdir ORB_SLAM cd ORB_SLAM 2. I... -
Evolutionary Approach to Approximate Digital Circuits Design 1 This paper proposed the automatic design process to evolv...

