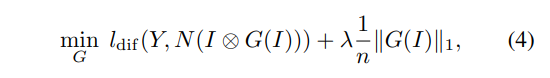How to use usb_cam with ros kinetic on jetson tx2
Nvidia Jetson TX2
Ubuntu 16.04
ROS Kinetic
1. Create a new workspace catkin_ws in the root directory
mkdir -p ~/catkin_ws/src
cd catkin_ws/src/
2. Download usb_cam package
git clone https://github.com/bosch-ros-pkg/usb_cam.git
3. Go to the workspace directory to compile
cd ~/catkin_ws
catkin_make
4. Compile the specific information:
Base path: /home/nvidia/catkin_ws
Source space: /home/nvidia/catkin_ws/src
Build space: /home/nvidia/catkin_ws/build
Devel space: /home/nvidia/catkin_ws/devel
Install space: /home/nvidia/catkin_ws/install
Creating symlink "/home/nvidia/catkin_ws/src/CMakeLists.txt" pointing to "/opt/ros/kinetic/share/catkin/cmake/toplevel.cmake"
####
#### Running command: "cmake /home/nvidia/catkin_ws/src -DCATKIN_DEVEL_PREFIX=/home/nvidia/catkin_ws/devel -DCMAKE_INSTALL_PREFIX=/home/nvidia/catkin_ws/install -G Unix Makefiles" in "/home/nvidia/catkin_ws/build"
####
-- The C compiler identification is GNU 5.4.0
-- The CXX compiler identification is GNU 5.4.0
-- Check for working C compiler: /usr/bin/cc
-- Check for working C compiler: /usr/bin/cc -- works
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Detecting C compile features
-- Detecting C compile features - done
-- Check for working CXX compiler: /usr/bin/c++
-- Check for working CXX compiler: /usr/bin/c++ -- works
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Using CATKIN_DEVEL_PREFIX: /home/nvidia/catkin_ws/devel
-- Using CMAKE_PREFIX_PATH: /opt/ros/kinetic
-- This workspace overlays: /opt/ros/kinetic
-- Found PythonInterp: /usr/bin/python (found version "2.7.12")
-- Using PYTHON_EXECUTABLE: /usr/bin/python
-- Using Debian Python package layout
-- Using empy: /usr/bin/empy
-- Using CATKIN_ENABLE_TESTING: ON
-- Call enable_testing()
-- Using CATKIN_TEST_RESULTS_DIR: /home/nvidia/catkin_ws/build/test_results
-- Looking for pthread.h
-- Looking for pthread.h - found
-- Looking for pthread_create
-- Looking for pthread_create - not found
-- Looking for pthread_create in pthreads
-- Looking for pthread_create in pthreads - not found
-- Looking for pthread_create in pthread
-- Looking for pthread_create in pthread - found
-- Found Threads: TRUE
-- Found gtest sources under '/usr/src/gtest': gtests will be built
-- Using Python nosetests: /usr/bin/nosetests-2.7
-- catkin 0.7.6
-- BUILD_SHARED_LIBS is on
-- ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-- ~~ traversing 1 packages in topological order:
-- ~~ - usb_cam
-- ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-- +++ processing catkin package: 'usb_cam'
-- ==> add_subdirectory(usb_cam)
-- Found PkgConfig: /usr/bin/pkg-config (found version "0.29.1")
-- Checking for module 'libavcodec'
-- Found libavcodec, version 56.60.100
-- Checking for module 'libswscale'
-- Found libswscale, version 3.1.101
-- Configuring done
-- Generating done
-- Build files have been written to: /home/nvidia/catkin_ws/build
####
#### Running command: "make -j4 -l4" in "/home/nvidia/catkin_ws/build"
####
Scanning dependencies of target usb_cam
[ 25%] Building CXX object usb_cam/CMakeFiles/usb_cam.dir/src/usb_cam.cpp.o
[ 50%] Linking CXX shared library /home/nvidia/catkin_ws/devel/lib/libusb_cam.so
[ 50%] Built target usb_cam
Scanning dependencies of target usb_cam_node
[ 75%] Building CXX object usb_cam/CMakeFiles/usb_cam_node.dir/nodes/usb_cam_node.cpp.o
[100%] Linking CXX executable /home/nvidia/catkin_ws/devel/lib/usb_cam/usb_cam_node
[100%] Built target usb_cam_node
5. Environment variable update operation
source ~/catkin_ws/devel/setup.bash
6. Open the camera startup configuration file usb_cam-test.launch in the workspace directory.
cd ~/catkin_ws/src/usb_cam/launch
gedit usb_cam-test.launch
7. The usb_cam-test.launch file information is as follows:
<launch>
<node name="usb_cam" pkg="usb_cam" type="usb_cam_node" output="screen" >
<param name="video_device" value="/dev/video1" />
<param name="image_width" value="640" />
<param name="image_height" value="480" />
<param name="pixel_format" value="yuyv" />
<param name="camera_frame_id" value="usb_cam" />
<param name="io_method" value="mmap"/>
</node>
<node name="image_view" pkg="image_view" type="image_view" respawn="false" output="screen">
<remap from="image" to="/usb_cam/image_raw"/>
<param name="autosize" value="true" />
</node>
</launch>
8. Since the TX2 comes with an onboard camera, the performance of the onboard camera ("/dev/video0") is not good, so we recommend using a take-away camera. Need to adjust the value of the video_device value to "/dev/video1"
9. Execute the following command to call the camera
roslaunch usb_cam-test.launch
10. The results of the operation:
... logging to /home/nvidia/.ros/log/4b9c8574-9072-11e7-bf53-00044b8caad5/roslaunch-tegra-ubuntu-3059.log
Checking log directory for disk usage. This may take awhile.
Press Ctrl-C to interrupt
Done checking log file disk usage. Usage is <1GB.
started roslaunch server http://tegra-ubuntu:35309/
SUMMARY
========
PARAMETERS
* /image_view/autosize: True
* /rosdistro: kinetic
* /rosversion: 1.12.7
* /usb_cam/camera_frame_id: usb_cam
* /usb_cam/image_height: 480
* /usb_cam/image_width: 640
* /usb_cam/io_method: mmap
* /usb_cam/pixel_format: yuyv
* /usb_cam/video_device: /dev/video1
NODES
/
image_view (image_view/image_view)
usb_cam (usb_cam/usb_cam_node)
ROS_MASTER_URI=http://localhost:11311
core service [/rosout] found
process[usb_cam-1]: started with pid [3078]
process[image_view-2]: started with pid [3079]
init done
[ INFO] [1504421929.509447030]: Using transport "raw"
[ INFO] [1504421929.756668326]: using default calibration URL
[ INFO] [1504421929.757037809]: camera calibration URL: file:///home/nvidia/.ros/camera_info/head_camera.yaml
[ INFO] [1504421929.757321401]: Unable to open camera calibration file [/home/nvidia/.ros/camera_info/head_camera.yaml]
[ WARN] [1504421929.757445853]: Camera calibration file /home/nvidia/.ros/camera_info/head_camera.yaml not found.
[ INFO] [1504421929.757588513]: Starting 'head_camera' (/dev/video1) at 640x480 via mmap (yuyv) at 30 FPS
[ WARN] [1504421930.977394215]: unknown control 'focus_auto'
The pop-up camera screen will appear on your monitor.