
최근, CNN은 monocular depth estimation이라는 과제에서 큰 성공을 거두고 있다.
그런데 CNN이 어떻게 하나의 이미지에서 깊이를 유추할 수 있는가?
우리는 깊이 추정에 필요한 입력 이미지 픽셀을 구분해 CNN 추정을 시각화하겠다.
Optimization Problem: CNN이 depth map을 추정할 수 있는 최소 이미지 픽셀 수 찾기
CNN이 깊어서 최적화가 어려우면 다른 네트워크를 사용할 것을 제안한다.
이 최적화 문제(시각화)를 실내와 실외 장면 데이터 세트의 서로 다른 depth estimation network에 적용해서 reasonable한지 보자.

- 인간이 depth 추정을 위해 고려하는 6가지: linear perspective, texture gradient, aerial perspective, relative size, interposition, light and shades
- CNN의 depth 추정과 관련된 픽셀들
Proposed Approach

Optimization Problem
- RGB image로 Predicted Mask(M) 생성 - RGB image의 일부
- RGB image로 얻은 depth map과 M으로 얻은 depth map을 비교해서 (1)둘이 가장 비슷하고 (2)가장 작은 픽셀 수를 갖는 M 찾기.
- G: M 찾는 net
- N: depth estimation하는 net

Optimization formula 찾기. 3개로 실험해 본 결과 (c)가 제일 나아서 그걸로 학습함.
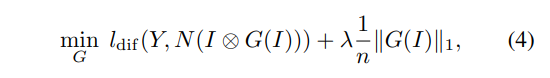


KITTI dataset에서 CNN이 이미지를 이렇게 보더라
CNN이 이미지를 이렇게 본다.
- Edge 중요
- Object이 있으면 내부 region을 고려함
- 소실점은 항상 중요하게 고려됨


No comments:
Post a Comment