FASTER and better: A machine learning approach to corner detection
FAST알고리즘을 이용한 특징 검출
- 이미지에서 픽셀 p를 선택. 이 때, 선택한 p의 밝기는 Ip.
- 적당한 threshold t를 정함.
- p주위의 원 내부에 lp+t보다 밝은 픽셀이 n개 연속으로 존재하거나, Ip-t 보다 어두운 픽셀이 n개 연속으로 존재하면 픽셀 p를 코너로 판단. (논문에서 n은 12)

이 detector는 아주 좋은 성능을 보여주지만, 몇가지 단점이 있음
- This high-speed test does not reject as many candidates for n < 12 since the point can be a corner if only two out of the four pixels are both significantly brighter or both significantly darker than p (assuming the pixels are adjacent). Additional tests are also required to find if the complete test needs to be performed for a bright ring or a dark ring.
- 과연 12라는 n이 적당한가?
- The efficiency of the detector will depend on the ordering of the questions and the distribution of corner appearances. It is unlikely that this choice of pixels is optimal.
- p를 어떻게 선택할 것인가?
- Multiple features are detected adjacent to one another.
- p주위로 여러 features들이 나타날 수 있지 않는지?
이 약점 세가지는 machine learning으로 극복할 수 있음
- 코너 검출을 위한 machine learning
- Training을 위한 image dataset 선택
- Features를 찾기 위해 모든 이미지에 FAST 알고리즘 실행
- 검출된 모든 픽셀에 대해 픽셀 주위로 16개 픽셀을 벡터로 저장 (이 벡터를 P라고 하자)
- 그렇다면 그 픽셀들은 이렇게 나타낼 수 있음:
- 이 함수에 따라 벡터 P는 Pd(darker), Ps(similar), Pb(brighter)로 나타낼 수 있음
- 이것으로 새로운 boolean 변수 Kp를 정의 -> p가 코너면 true, 아니면 false
- Pd, Ps, Pb에 Kp변수를 이용해 코너를 빠르게 검출하는 의사결정 트리 생성
- Non-maximal Suppression
- 검출된 feature points에 대해 p와 주변 픽셀 16개의 차 절대값을 모두 더한 값인 V 계산
- 인접한 2개의 key point의 V를 비교해 작은 것을 버린다.
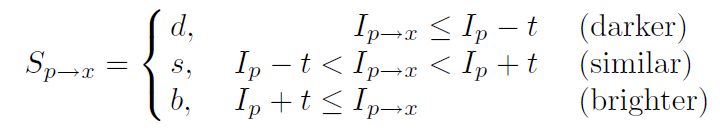
한계!
FAST는 아주 빠르지만 노이즈가 많으면 잘 안되고, threshold 값에 의존적임…


No comments:
Post a Comment