[1] Scale Invariant Feature Transform - David Lowe
- What is SIFT?
- Image에서 중요한 feature points를 찾는 기술
- Features?: 포인트 주변을 잘 설명해주는 정보. rotation, scale과 관련 있음
- Motivation for SIFT
- Image matching
- 이미지들 사이의 affine transformation과 homography를 추정하는 것
- Fundamental matric in stereo 추정 (카메라 여러대?)
- Motion, tracking, motion segmentation의 구조 파악
- 이미지들의 중요하고 stable한 points 찾기 & 이것들 사이의 관계 결정하기
- Feature는 물체 위치, 자세, 스케일, 조도, 노이즈 등에 무관해야 함
- Individual pixel colour values are not an adequate feature to determine correspondences (?)
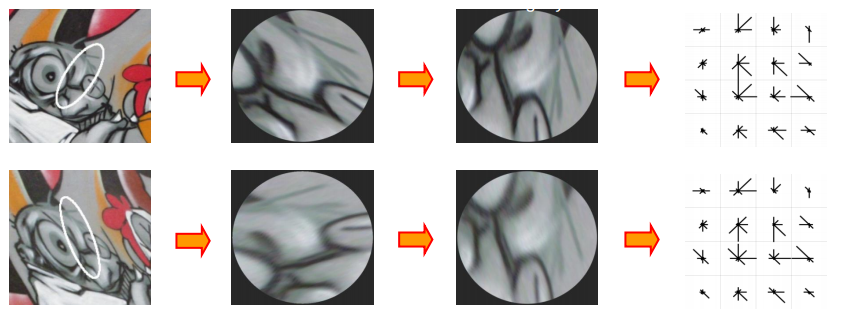
SIFT는 변화(회전이나 스케일)에 관계없이 feature를 잘 찾아냄. 위의 그림에서 같은 것으로 잘 인식하는 것을 볼 수 있음. (서로 다른 두 이미지에서 SIFT특징을 각각 추출한 다음에 가장 비슷한 특징끼리 매칭해주면 두 이미지에서 대을되는 부분을 찾을 수 있음.)
- Steps of SIFT algorithm
- Step 1) Scale Space 만들기
- Scale Space란?
- 영상처리를 할 때 단 하나의 스케일을 가진 이미지가 아니라 여러 스케일로 본 이미지들을 가지고 작업하는 것 -> 이 이미지 뭉치가 바로 Scale Space
- 스케일이 커질수록 디테일한 것이 잘 안보임 -> 이미지 사이즈는 유지하면서 blur처리를 하면 스케일이 커진 것과 같은 효과를 볼 수 있음
- Blur처리를 어떻게 하는지? -> Gaussian Filter를 이용한다.

스케일 파라미터 σ가 커질수록 스케일이 커진다.
- 원본 이미지를 2배, 1/2배, 1/4배로 만들어서 스케일 파라미터를 다르게 총 4세트를 만든다.
이게 바로 Scale Space
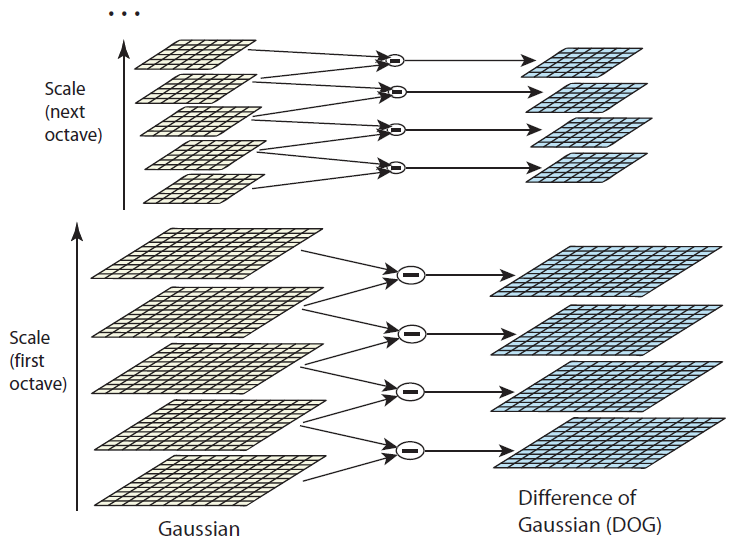
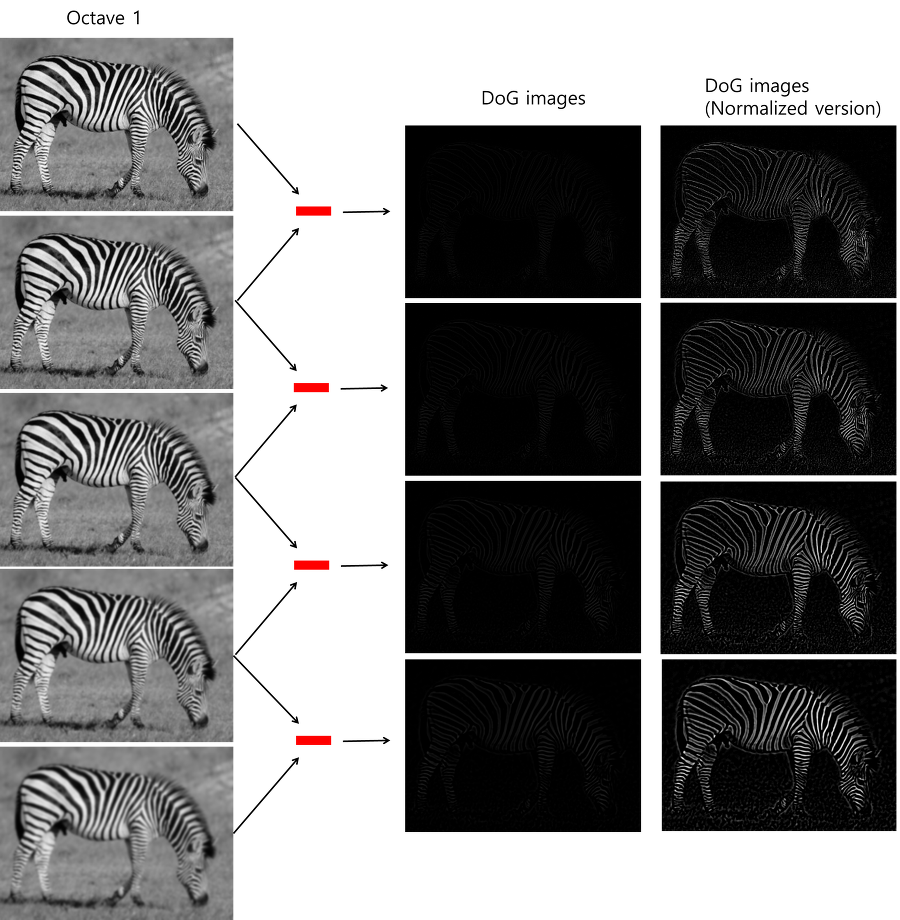
- Step 2) DoG 연산 (Difference of Gaussian)
- Laplacian of Gaussian(LoG)를 이용해서 이미지 내의 key points를 찾는다.
- Blur -> 2차미분
- but, 이 녀석은 계산이 너무 많음
- Difference of Gaussian(DoG)
- 라플라시안을 구하는 것을 컨볼루션을 해야하지만, DoG는 화소값의 차이만 구하면 되므로 계산이 수십배에서 수백배로 빨라짐.
- 같은 옥타브 내에서 인접한 두개의 블러 이미지들끼리 빼줌
- Step 3) Key point들 찾기
- 한 픽셀에서 극대값, 극소값을 결정할 때는 동일한 octave내의 3장의 DoG이미지가 필요함. 지금 체크할 픽셀 주변의 8개 픽셀과, scale이 한단계씩 다른 위 아래 두 DoG 이미지에서 체크하려고 하는 픽셀과 가까운 9개씩, 총 26개를 검사합니다. 만약 지금 체크하는 픽셀의 값이 26개의 이웃 픽셀값 중에 가장 작거나 가장 클 때 keypoint로 인정.
테일러 2차 전개를 이용, 픽셀 사이의 정확한 키 포인트를 찾아낸다.
- Step 4) 나쁜 Key point들 제거하기
- 활용가치가 떨어지는 것들을 제거
- 낮은 콘트라스트를 가지고 있거나(threshold 이하)
- 엣지 위에 있는 것
- 코너에 있는 키포인트들이 좋은 것임
- Step 5) key points에 방향 할당해주기
- 지금까지 얻은 키포인트는 scale invariance를 만족, 지금부터는 rotation invariance를 위한 것.
- Key point 주변의 그래디언트 방향과 크기를 활용, 가장 큰 그래디언트의 방향이 키포인트의 방향이 된다.
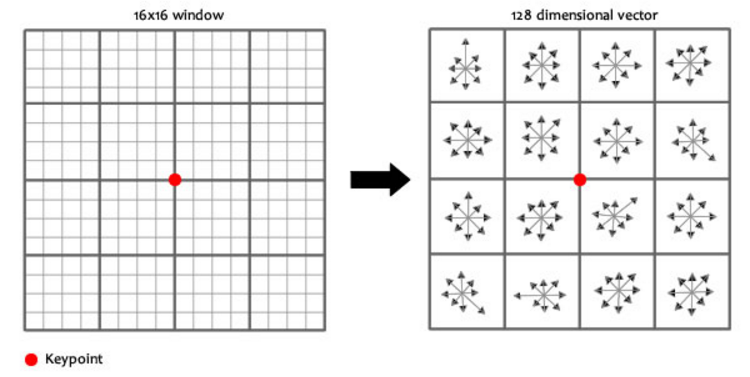
- Step 6) 최종 SIFT 특징 산출
- 지금까지 얻은 키포인트들은 scale, rotation 불변성을 가지고 있음
- 이것들을 식별하기 위한 정보(지문) 부여(그래디언트의 크기와 방향)
- 그렇다면 SIFT로 이미지 매칭을 어떻게 하는 것일까요? 먼저 두 이미지에서 각각 keypoint들을 찾고 지문을 달아줬다면, 이 지문값들의 차이가 가장 작은 곳이 서로 매칭되는 위치인 것입니다.
- 장단점
- 장점
- Affine transformation에 강건
- Illumination changes에 강건
- 단점
- 3D 물체보다 평면에서 작동이 잘됨
- Several parameters in the algorithm: descriptor size, size of the region, various thresholds – theoretical treatment for their specification not clear